roadmap.sh is a community effort to create roadmaps, guides and other educational content to help guide developers in picking up a path and guide their learnings.
Developer Roadmaps: Charting Your Course to Success
In the ever-evolving world of technology, staying ahead of the curve requires a strategic approach to learning and development. This is where developer roadmaps come in. A developer roadmap acts as a personalized guide, outlining the skills, technologies, and experiences needed to progress in your chosen tech career path. Whether you’re a beginner just starting out or an experienced developer looking to specialize, a roadmap can provide clarity, direction, and motivation.
Benefits of Using Developer Roadmaps
Embracing a structured learning path through a developer roadmap offers numerous benefits:
Clarity and Focus: Roadmaps break down complex tech landscapes into manageable chunks, helping you identify specific areas to focus on and avoid feeling overwhelmed.
Goal Setting and Tracking: By outlining clear milestones and objectives, roadmaps enable you to set realistic goals and track your progress effectively.
Skill Development: Roadmaps highlight essential skills and technologies, ensuring you acquire a well-rounded skillset relevant to your desired career path.
Career Advancement: A comprehensive roadmap demonstrates your commitment to continuous learning and can significantly enhance your career prospects.
Crafting Your Personalized Roadmap
Building a successful developer roadmap involves several key steps:
Define Your Goals: Start by clearly articulating your career aspirations. What specific role or industry are you targeting? What type of projects do you envision yourself working on?
Research Industry Trends: Stay informed about the latest technologies and in-demand skills in your chosen field. Explore online resources, industry reports, and professional networks to gain insights.
Identify Essential Skills: Based on your goals and industry research, pinpoint the core technical skills and soft skills required for success.
Create a Learning Plan: Break down your skill development journey into manageable steps. Outline specific courses, projects, or certifications to pursue.
Track Your Progress and Adjust: Regularly review your roadmap, assess your progress, and make adjustments as needed. The tech landscape is constantly evolving, so flexibility is crucial.
Resources for Developer Roadmaps
Numerous online platforms and communities offer valuable resources for creating and following developer roadmaps:
roadmap.sh: This comprehensive platform provides curated roadmaps for various tech roles and specializations.
GitHub: Explore open-source projects and contribute to real-world development experiences.
Stack Overflow: Engage in discussions, ask questions, and learn from a vast community of developers.
Online Learning Platforms: Platforms like Coursera, Udemy, and edX offer a wide range of courses and certifications to enhance your skillset.
By leveraging these resources and adopting a structured approach, you can create a personalized developer roadmap that empowers you to achieve your tech career goals. Remember, continuous learning and adaptation are essential for thriving in the dynamic world of software development.
Tauri 2.0 is a significant leap forward for the Tauri framework, bringing enhanced performance, new features, and a streamlined development experience. This modern framework empowers developers to build high-performance, cross-platform desktop applications using familiar web technologies like HTML, CSS, and JavaScript.
Leveraging Web Technologies for Desktop Apps
One of Tauri’s core strengths lies in its ability to leverage the vast ecosystem of web technologies. Developers can utilize their existing JavaScript skills and libraries to create rich and interactive user interfaces. Tauri’s integration with popular frameworks like React, Vue, and Svelte further simplifies the development process, allowing teams to adopt their preferred front-end technologies.
This approach offers several advantages. Firstly, it eliminates the need to learn new programming languages or frameworks specifically for desktop development. Secondly, the extensive tooling and support available for web technologies translate directly to Tauri development, ensuring a smoother and more efficient workflow.
Rust-Powered Performance and Security
Underneath Tauri’s web-friendly facade lies a robust and performant core written in Rust. Rust’s reputation for memory safety and speed makes Tauri an ideal choice for building applications that demand high performance and reliability.
The use of Rust also enhances the security of Tauri applications. Rust’s strict type system and memory management features help prevent common vulnerabilities like buffer overflows and dangling pointers. This inherent security makes Tauri an attractive option for building applications that handle sensitive user data or require strict security protocols.
Cross-Platform Compatibility
Tauri’s commitment to cross-platform compatibility allows developers to reach a wider audience. With a single codebase, developers can deploy their applications on Windows, macOS, and Linux, ensuring a consistent user experience across different operating systems.
This cross-platform capability is particularly valuable for businesses targeting a global user base. By eliminating the need for platform-specific development, Tauri streamlines the deployment process and reduces development costs.
Embracing the Future of Desktop Development
Tauri 2.0 represents a significant milestone in the evolution of desktop application development. By combining the power of Rust, the accessibility of web technologies, and a focus on performance and security, Tauri empowers developers to build modern, high-quality desktop applications that meet the demands of today’s users.
Whether you’re a seasoned developer or just starting your journey into desktop app development, Tauri 2.0 offers a compelling platform for creating innovative and engaging applications.
Free and Open Source Hex Editor for all OSes and the Web ImHex is a Hex Editor, a tool to display, decode and analyze binary data to reverse engineer their format, extract informations or patch values in them.
What makes ImHex special is that it has many advanced features that can often only be found in paid applications.
Such features are a completely custom binary template and pattern language to decode and highlight structures in the data, a graphical node-based data processor to pre-process values before they’re displayed,
a disassembler, diffing support, bookmarks and much much more.
At the same time ImHex is completely free and open source under the GPLv2 license.
Dear ImGui is a bloat-free graphical user interface library for C++. It outputs optimized vertex buffers that you can render anytime in your 3D-pipeline-enabled application. It is fast, portable, renderer agnostic, and self-contained (no external dependencies).
Dear ImGui is designed to enable fast iterations and to empower programmers to create content creation tools and visualization / debug tools (as opposed to UI for the average end-user). It favors simplicity and productivity toward this goal and lacks certain features commonly found in more high-level libraries. Among other things, full internationalization (right-to-left text, bidirectional text, text shaping etc.) and accessibility features are not supported.
Dear ImGui is particularly suited to integration in game engines (for tooling), real-time 3D applications, fullscreen applications, embedded applications, or any applications on console platforms where operating system features are non-standard.
Minimize state synchronization.
Minimize UI-related state storage on user side.
Minimize setup and maintenance.
Easy to use to create dynamic UI which are the reflection of a dynamic data set.
Easy to use to create code-driven and data-driven tools.
Easy to use to create ad hoc short-lived tools and long-lived, more elaborate tools.
Easy to hack and improve.
Portable, minimize dependencies, run on target (consoles, phones, etc.).
Nix is a tool that takes a unique approach to package management and system configuration. Learn how to make reproducible, declarative and reliable systems.
DuckDB is a cutting-edge, in-process SQL OLAP database management system gaining traction in the developer community. It’s designed to provide high-performance data analysis and querying capabilities directly within your application. Unlike traditional databases that require separate processes and connections, DuckDB operates entirely within your program’s memory, leading to significant performance gains.
The Advantages of In-Process Data Management
One of the key advantages of DuckDB is its in-process architecture. By residing within your application’s memory, DuckDB eliminates the overhead associated with network communication and process management. This results in faster query execution times and reduced latency, making it ideal for applications requiring real-time data insights.
Furthermore, DuckDB’s lightweight nature allows it to be easily integrated into various development environments. Its compact footprint and minimal dependencies make it a versatile choice for both small and large-scale projects.
DuckDB’s Robust SQL Support
DuckDB fully supports the standard SQL dialect, enabling developers to leverage their existing SQL knowledge and expertise. Whether you’re performing complex aggregations, joins, or analytical queries, DuckDB provides a familiar and powerful interface.
Its support for window functions, common table expressions (CTEs), and other advanced SQL features empowers developers to build sophisticated data analysis pipelines. DuckDB’s commitment to SQL compliance ensures seamless integration with existing data workflows and tools.
Use Cases for DuckDB
DuckDB’s unique capabilities make it suitable for a wide range of applications, including:
Data Exploration and Analysis: Quickly analyze and explore data within your application, enabling data-driven decision-making.
Real-Time Data Processing: Handle real-time data streams and perform immediate analysis, crucial for applications like fraud detection or anomaly monitoring.
Embedded Analytics: Integrate analytical capabilities directly into your applications, providing users with on-demand insights without relying on external databases.
Data Warehousing: Utilize DuckDB as a lightweight data warehouse for smaller datasets, offering fast query performance and ease of management.
Getting Started with DuckDB
DuckDB’s user-friendly documentation and active community make it easy to get started.
The official website provides comprehensive tutorials, examples, and API references to guide you through the process: https://duckdb.org/.
Conclusion
DuckDB represents a compelling choice for developers seeking a high-performance, in-process SQL OLAP database solution. Its speed, ease of integration, and robust SQL support make it a valuable asset for a wide range of data-driven applications.
In today’s fast-paced development environment, efficient project management is paramount. Huly emerges as a powerful all-in-one platform designed to revolutionize the way development teams collaborate and deliver projects. As an alternative to popular tools like Linear, Jira, Slack, Notion, and Motion, Huly offers a comprehensive suite of features to manage tasks, track progress, and foster seamless communication.
Centralized Project Hub:
Huly provides a centralized hub for all your project needs, eliminating the need to juggle multiple applications. From task creation and assignment to progress tracking and reporting, everything is seamlessly integrated within a single platform. This centralized approach fosters a clear overview of project status, enabling teams to stay aligned and on track.
Imagine a scenario where your development team is working on a complex software project. With Huly, you can create detailed project boards, break down tasks into manageable subtasks, assign responsibilities, set deadlines, and monitor progress in real-time. The intuitive interface allows for easy navigation and collaboration, ensuring that everyone is on the same page.
Enhanced Communication and Collaboration:
Effective communication is the cornerstone of successful project management. Huly fosters seamless communication within development teams through integrated chat, file sharing, and commenting features.
Developers can easily discuss project updates, share code snippets, and provide feedback directly within the platform. This eliminates the need for email threads and external communication channels, streamlining the workflow and keeping everyone informed.
Customization and Flexibility:
Huly recognizes that every development team has unique needs and workflows. The platform offers a high degree of customization, allowing teams to tailor it to their specific requirements.
From customizable project boards and task views to integrations with popular development tools, Huly adapts to your team’s preferences. This flexibility ensures that Huly remains a valuable asset regardless of the project’s complexity or the team’s size.
Seamless Integrations:
Huly integrates seamlessly with a wide range of popular development tools, further enhancing its value proposition. Whether you’re using Git for version control, Slack for team communication, or other essential development tools, Huly can be integrated to streamline your workflow.
These integrations eliminate the need for manual data transfer and ensure that all your project-related information is centralized and readily accessible.
This notebook demonstrates the use of the logprobs parameter in the Chat Completions API. When logprobs is enabled, the API returns the log probabilities of each output token, along with a limited number of the most likely tokens at each token position and their log probabilities. The relevant request parameters are:
logprobs: Whether to return log probabilities of the output tokens or not. If true, returns the log probabilities of each output token returned in the content of message. This option is currently not available on the gpt-4-vision-preview model.
top_logprobs: An integer between 0 and 5 specifying the number of most likely tokens to return at each token position, each with an associated log probability. logprobs must be set to true if this parameter is used.
Log probabilities of output tokens indicate the likelihood of each token occurring in the sequence given the context. To simplify, a logprob is log(p), where p = probability of a token occurring at a specific position based on the previous tokens in the context. Some key points about logprobs:
Higher log probabilities suggest a higher likelihood of the token in that context. This allows users to gauge the model's confidence in its output or explore alternative responses the model considered.
Logprob can be any negative number or 0.0. 0.0 corresponds to 100% probability.
Logprobs allow us to compute the joint probability of a sequence as the sum of the logprobs of the individual tokens. This is useful for scoring and ranking model outputs. Another common approach is to take the average per-token logprob of a sentence to choose the best generation.
We can examine the logprobs assigned to different candidate tokens to understand what options the model considered plausible or implausible.
While there are a wide array of use cases for logprobs, this notebook will focus on its use for:
Classification tasks
Large Language Models excel at many classification tasks, but accurately measuring the model's confidence in its outputs can be challenging. logprobs provide a probability associated with each class prediction, enabling users to set their own classification or confidence thresholds.
Retrieval (Q&A) evaluation
logprobs can assist with self-evaluation in retrieval applications. In the Q&A example, the model outputs a contrived has_sufficient_context_for_answer boolean, which can serve as a confidence score of whether the answer is contained in the retrieved content. Evaluations of this type can reduce retrieval-based hallucinations and enhance accuracy.
Autocomplete
logprobs could help us decide how to suggest words as a user is typing.
Token highlighting and outputting bytes
Users can easily create a token highlighter using the built in tokenization that comes with enabling logprobs. Additionally, the bytes parameter includes the ASCII encoding of each output character, which is particularly useful for reproducing emojis and special characters.
Calculating perplexity
logprobs can be used to help us assess the model's overall confidence in a result and help us compare the confidence of results from different prompts.
from openai import OpenAIfrom math import expimport numpy as npfrom IPython.display import display, HTMLimport osclient = OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "<your OpenAI API key if not set as env var>"))
defget_completion( messages: list[dict[str, str]], model: str="gpt-4", max_tokens=500, temperature=0, stop=None, seed=123, tools=None, logprobs=None, # whether to return log probabilities of the output tokens or not. If true, returns the log probabilities of each output token returned in the content of message.. top_logprobs=None,) -> str: params = {"model": model,"messages": messages,"max_tokens": max_tokens,"temperature": temperature,"stop": stop,"seed": seed,"logprobs": logprobs,"top_logprobs": top_logprobs, }if tools: params["tools"] = tools completion = client.chat.completions.create(**params)return completion
Let's say we want to create a system to classify news articles into a set of pre-defined categories. Without logprobs, we can use Chat Completions to do this, but it is much more difficult to assess the certainty with which the model made its classifications.
Now, with logprobs enabled, we can see exactly how confident the model is in its predictions, which is crucial for creating an accurate and trustworthy classifier. For example, if the log probability for the chosen category is high, this suggests the model is quite confident in its classification. If it's low, this suggests the model is less confident. This can be particularly useful in cases where the model's classification is not what you expected, or when the model's output needs to be reviewed or validated by a human.
We'll begin with a prompt that presents the model with four categories: Technology, Politics, Sports, and Arts. The model is then tasked with classifying articles into these categories based solely on their headlines.
CLASSIFICATION_PROMPT="""You will be given a headline of a news article.Classify the article into one of the following categories: Technology, Politics, Sports, and Art.Return only the name of the category, and nothing else.MAKE SURE your output is one of the four categories stated.Article headline: {headline}"""
Let's look at three sample headlines, and first begin with a standard Chat Completions output, without logprobs
headlines = ["Tech Giant Unveils Latest Smartphone Model with Advanced Photo-Editing Features.","Local Mayor Launches Initiative to Enhance Urban Public Transport.","Tennis Champion Showcases Hidden Talents in Symphony Orchestra Debut",]
for headline in headlines:print(f"\nHeadline: {headline}")API_RESPONSE= get_completion( [{"role": "user", "content": CLASSIFICATION_PROMPT.format(headline=headline)}],model="gpt-4", )print(f"Category: {API_RESPONSE.choices[0].message.content}\n")
Headline: Tech Giant Unveils Latest Smartphone Model with Advanced Photo-Editing Features.
Category: Technology
Headline: Local Mayor Launches Initiative to Enhance Urban Public Transport.
Category: Politics
Headline: Tennis Champion Showcases Hidden Talents in Symphony Orchestra Debut
Category: Art
Here we can see the selected category for each headline. However, we have no visibility into the confidence of the model in its predictions. Let’s rerun the same prompt but with logprobs enabled, and top_logprobs set to 2 (this will show us the 2 most likely output tokens for each token). Additionally we can also output the linear probability of each output token, in order to convert the log probability to the more easily interprable scale of 0-100%.
for headline in headlines:print(f”\nHeadline: {headline}”)API_RESPONSE= get_completion( [{“role”: “user”, “content”: CLASSIFICATION_PROMPT.format(headline=headline)}],model=“gpt-4”,logprobs=True,top_logprobs=2, ) top_two_logprobs =API_RESPONSE.choices[0].logprobs.content[0].top_logprobs html_content =””for i, logprob inenumerate(top_two_logprobs, start=1): html_content += (f”Output token {i}:{logprob.token}, “f”logprobs:{logprob.logprob}, “f”linear probability:{np.round(np.exp(logprob.logprob)*100,2)}% ” ) display(HTML(html_content))print(”\n”)
Headline: Tech Giant Unveils Latest Smartphone Model with Advanced Photo-Editing Features.
Output token 1: Technology, logprobs: -2.4584822e-06, linear probability: 100.0% Output token 2: Techn, logprobs: -13.781253, linear probability: 0.0%
Headline: Local Mayor Launches Initiative to Enhance Urban Public Transport.
Output token 1: Politics, logprobs: -2.4584822e-06, linear probability: 100.0% Output token 2: Technology, logprobs: -13.937503, linear probability: 0.0%
Headline: Tennis Champion Showcases Hidden Talents in Symphony Orchestra Debut
Output token 1: Art, logprobs: -0.009169078, linear probability: 99.09% Output token 2: Sports, logprobs: -4.696669, linear probability: 0.91%
As expected from the first two headlines, gpt-4 is nearly 100% confident in its classifications, as the content is clearly technology and politics focused respectively. However, the third headline combines both sports and art-related themes, so we see the model is less confident in its selection.
This shows how important using logprobs can be, as if we are using LLMs for classification tasks we can set confidence theshholds, or output several potential output tokens if the log probability of the selected output is not sufficiently high. For instance, if we are creating a recommendation engine to tag articles, we can automatically classify headlines crossing a certain threshold, and send the less certain headlines for manual review.
To reduce hallucinations, and the performance of our RAG-based Q&A system, we can use logprobs to evaluate how confident the model is in its retrieval.
Let's say we have built a retrieval system using RAG for Q&A, but are struggling with hallucinated answers to our questions. Note: we will use a hardcoded article for this example, but see other entries in the cookbook for tutorials on using RAG for Q&A.
# Article retrievedada_lovelace_article ="""Augusta Ada King, Countess of Lovelace (née Byron; 10 December 1815 – 27 November 1852) was an English mathematician and writer, chiefly known for her work on Charles Babbage's proposed mechanical general-purpose computer, the Analytical Engine. She was the first to recognise that the machine had applications beyond pure calculation.Ada Byron was the only legitimate child of poet Lord Byron and reformer Lady Byron. All Lovelace's half-siblings, Lord Byron's other children, were born out of wedlock to other women. Byron separated from his wife a month after Ada was born and left England forever. He died in Greece when Ada was eight. Her mother was anxious about her upbringing and promoted Ada's interest in mathematics and logic in an effort to prevent her from developing her father's perceived insanity. Despite this, Ada remained interested in him, naming her two sons Byron and Gordon. Upon her death, she was buried next to him at her request. Although often ill in her childhood, Ada pursued her studies assiduously. She married William King in 1835. King was made Earl of Lovelace in 1838, Ada thereby becoming Countess of Lovelace.Her educational and social exploits brought her into contact with scientists such as Andrew Crosse, Charles Babbage, Sir David Brewster, Charles Wheatstone, Michael Faraday, and the author Charles Dickens, contacts which she used to further her education. Ada described her approach as "poetical science" and herself as an "Analyst (& Metaphysician)".When she was eighteen, her mathematical talents led her to a long working relationship and friendship with fellow British mathematician Charles Babbage, who is known as "the father of computers". She was in particular interested in Babbage's work on the Analytical Engine. Lovelace first met him in June 1833, through their mutual friend, and her private tutor, Mary Somerville.Between 1842 and 1843, Ada translated an article by the military engineer Luigi Menabrea (later Prime Minister of Italy) about the Analytical Engine, supplementing it with an elaborate set of seven notes, simply called "Notes".Lovelace's notes are important in the early history of computers, especially since the seventh one contained what many consider to be the first computer program—that is, an algorithm designed to be carried out by a machine. Other historians reject this perspective and point out that Babbage's personal notes from the years 1836/1837 contain the first programs for the engine. She also developed a vision of the capability of computers to go beyond mere calculating or number-crunching, while many others, including Babbage himself, focused only on those capabilities. Her mindset of "poetical science" led her to ask questions about the Analytical Engine (as shown in her notes) examining how individuals and society relate to technology as a collaborative tool."""# Questions that can be easily answered given the articleeasy_questions = ["What nationality was Ada Lovelace?","What was an important finding from Lovelace's seventh note?",]# Questions that are not fully covered in the articlemedium_questions = ["Did Lovelace collaborate with Charles Dickens","What concepts did Lovelace build with Charles Babbage",]
Now, what we can do is ask the model to respond to the question, but then also evaluate its response. Specifically, we will ask the model to output a boolean has_sufficient_context_for_answer. We can then evaluate the logprobs to see just how confident the model is that its answer was contained in the provided context
PROMPT="""You retrieved this article: {article}. The question is: {question}.Before even answering the question, consider whether you have sufficient information in the article to answer the question fully.Your output should JUST be the boolean true or false, of if you have sufficient information in the article to answer the question.Respond with just one word, the boolean true or false. You must output the word 'True', or the word 'False', nothing else."""
has_sufficient_context_for_answer: True, logprobs: -3.1281633e-07, linear probability: 100.0%
Question: What was an important finding from Lovelace's seventh note?
has_sufficient_context_for_answer: True, logprobs: -7.89631e-07, linear probability: 100.0%
Questions only partially covered in the article
Question: Did Lovelace collaborate with Charles Dickens
has_sufficient_context_for_answer: True, logprobs: -0.06993677, linear probability: 93.25%
Question: What concepts did Lovelace build with Charles Babbage
has_sufficient_context_for_answer: False, logprobs: -0.61807257, linear probability: 53.9%
For the first two questions, our model asserts with (near) 100% confidence that the article has sufficient context to answer the posed questions.
On the other hand, for the more tricky questions which are less clearly answered in the article, the model is less confident that it has sufficient context. This is a great guardrail to help ensure our retrieved content is sufficient.
This self-evaluation can help reduce hallucinations, as you can restrict answers or re-prompt the user when your sufficient_context_for_answer log probability is below a certain threshold. Methods like this have been shown to significantly reduce RAG for Q&A hallucinations and errors (Example)
Another use case for logprobs are autocomplete systems. Without creating the entire autocomplete system end-to-end, let's demonstrate how logprobs could help us decide how to suggest words as a user is typing.
First, let's come up with a sample sentence: "My least favorite TV show is Breaking Bad." Let's say we want it to dynamically recommend the next word or token as we are typing the sentence, but only if the model is quite sure of what the next word will be. To demonstrate this, let's break up the sentence into sequential components.
sentence_list = ["My","My least","My least favorite","My least favorite TV","My least favorite TV show","My least favorite TV show is","My least favorite TV show is Breaking Bad",]
Now, we can ask gpt-3.5-turbo to act as an autocomplete engine with whatever context the model is given. We can enable logprobs and can see how confident the model is in its prediction.
high_prob_completions = {}low_prob_completions = {}html_output =""for sentence in sentence_list:PROMPT="""Complete this sentence. You are acting as auto-complete. Simply complete the sentence to the best of your ability, make sure it is just ONE sentence: {sentence}"""API_RESPONSE= get_completion( [{"role": "user", "content": PROMPT.format(sentence=sentence)}],model="gpt-3.5-turbo",logprobs=True,top_logprobs=3, ) html_output +=f'<p>Sentence: {sentence}</p>' first_token =Truefor token inAPI_RESPONSE.choices[0].logprobs.content[0].top_logprobs: html_output +=f'<p style="color:cyan">Predicted next token: {token.token}, <span style="color:darkorange">logprobs: {token.logprob}, <span style="color:magenta">linear probability: {np.round(np.exp(token.logprob)*100,2)}%</span></p>'if first_token:if np.exp(token.logprob) >0.95: high_prob_completions[sentence] = token.tokenif np.exp(token.logprob) <0.60: low_prob_completions[sentence] = token.token first_token =False html_output +="<br>"display(HTML(html_output))
Sentence: My
Predicted next token: favorite, logprobs: -0.18245785, linear probability: 83.32%
Predicted next token: dog, logprobs: -2.397172, linear probability: 9.1%
Predicted next token: ap, logprobs: -3.8732424, linear probability: 2.08%
Sentence: My least
Predicted next token: favorite, logprobs: -0.0146376295, linear probability: 98.55%
Predicted next token: My, logprobs: -4.2417912, linear probability: 1.44%
Predicted next token: favorite, logprobs: -9.748788, linear probability: 0.01%
Sentence: My least favorite
Predicted next token: food, logprobs: -0.9481721, linear probability: 38.74%
Predicted next token: My, logprobs: -1.3447137, linear probability: 26.06%
Predicted next token: color, logprobs: -1.3887696, linear probability: 24.94%
Sentence: My least favorite TV
Predicted next token: show, logprobs: -0.0007898556, linear probability: 99.92%
Predicted next token: My, logprobs: -7.711523, linear probability: 0.04%
Predicted next token: series, logprobs: -9.348547, linear probability: 0.01%
Sentence: My least favorite TV show
Predicted next token: is, logprobs: -0.2851253, linear probability: 75.19%
Predicted next token: of, logprobs: -1.55335, linear probability: 21.15%
Predicted next token: My, logprobs: -3.4928775, linear probability: 3.04%
Sentence: My least favorite TV show is
Predicted next token: "My, logprobs: -0.69349754, linear probability: 49.98%
Predicted next token: "The, logprobs: -1.2899293, linear probability: 27.53%
Predicted next token: My, logprobs: -2.4170141, linear probability: 8.92%
Sentence: My least favorite TV show is Breaking Bad
Predicted next token: because, logprobs: -0.17786823, linear probability: 83.71%
Predicted next token: ,, logprobs: -2.3946173, linear probability: 9.12%
Predicted next token: ., logprobs: -3.1861975, linear probability: 4.13%
Let's look at the high confidence autocompletions:
high_prob_completions
{'My least': 'favorite', 'My least favorite TV': 'show'}
These look reasonable! We can feel confident in those suggestions. It's pretty likely you want to write 'show' after writing 'My least favorite TV'! Now let's look at the autocompletion suggestions the model was less confident about:
low_prob_completions
{'My least favorite': 'food', 'My least favorite TV show is': '"My'}
These are logical as well. It's pretty unclear what the user is going to say with just the prefix 'my least favorite', and it's really anyone's guess what the author's favorite TV show is.
So, using gpt-3.5-turbo, we can create the root of a dynamic autocompletion engine with logprobs!
Let's quickly touch on creating a simple token highlighter with logprobs, and using the bytes parameter. First, we can create a function that counts and highlights each token. While this doesn't use the log probabilities, it uses the built in tokenization that comes with enabling logprobs.
PROMPT="""What's the longest word in the English language?"""API_RESPONSE= get_completion( [{"role": "user", "content": PROMPT}], model="gpt-4", logprobs=True, top_logprobs=5)defhighlight_text(api_response): colors = ["#FF00FF", # Magenta"#008000", # Green"#FF8C00", # Dark Orange"#FF0000", # Red"#0000FF", # Blue ] tokens = api_response.choices[0].logprobs.content color_idx =0# Initialize color index html_output =""# Initialize HTML outputfor t in tokens: token_str =bytes(t.bytes).decode("utf-8") # Decode bytes to string# Add colored token to HTML output html_output +=f"<span style='color: {colors[color_idx]}'>{token_str}</span>"# Move to the next color color_idx = (color_idx +1) %len(colors) display(HTML(html_output)) # Display HTML outputprint(f"Total number of tokens: {len(tokens)}")
highlight_text(API_RESPONSE)
The longest word in the English language, according to the Guinness World Records, is 'pneumonoultramicroscopicsilicovolcanoconiosis'. It is a type of lung disease caused by inhaling ash and sand dust.
Total number of tokens: 51
Next, let's reconstruct a sentence using the bytes parameter. With logprobs enabled, we are given both each token and the ASCII (decimal utf-8) values of the token string. These ASCII values can be helpful when handling tokens of or containing emojis or special characters.
PROMPT="""Output the blue heart emoji and its name."""API_RESPONSE= get_completion( [{"role": "user", "content": PROMPT}], model="gpt-4", logprobs=True)aggregated_bytes = []joint_logprob =0.0# Iterate over tokens, aggregate bytes and calculate joint logprobfor token inAPI_RESPONSE.choices[0].logprobs.content:print("Token:", token.token)print("Log prob:", token.logprob)print("Linear prob:", np.round(exp(token.logprob) *100, 2), "%")print("Bytes:", token.bytes, "\n") aggregated_bytes += token.bytes joint_logprob += token.logprob# Decode the aggregated bytes to textaggregated_text =bytes(aggregated_bytes).decode("utf-8")# Assert that the decoded text is the same as the message contentassertAPI_RESPONSE.choices[0].message.content == aggregated_text# Print the resultsprint("Bytes array:", aggregated_bytes)print(f"Decoded bytes: {aggregated_text}")print("Joint prob:", np.round(exp(joint_logprob) *100, 2), "%")
Here, we see that while the first token was \xf0\x9f\x92’, we can get its ASCII value and append it to a bytes array. Then, we can easily decode this array into a full sentence, and validate with our assert statement that the decoded bytes is the same as our completion message!
Additionally, we can get the joint probability of the entire completion, which is the exponentiated product of each token's log probability. This gives us how likely this given completion is given the prompt. Since, our prompt is quite directive (asking for a certain emoji and its name), the joint probability of this output is high! If we ask for a random output however, we'll see a much lower joint probability. This can also be a good tactic for developers during prompt engineering.
When looking to assess the model's confidence in a result, it can be useful to calculate perplexity, which is a measure of the uncertainty. Perplexity can be calculated by exponentiating the negative of the average of the logprobs. Generally, a higher perplexity indicates a more uncertain result, and a lower perplexity indicates a more confident result. As such, perplexity can be used to both assess the result of an individual model run and also to compare the relative confidence of results between model runs. While a high confidence doesn't guarantee result accuracy, it can be a helpful signal that can be paired with other evaluation metrics to build a better understanding of your prompt's behavior.
For example, let's say that I want to use gpt-3.5-turbo to learn more about artificial intelligence. I could ask a question about recent history and a question about the future:
prompts = ["In a short sentence, has artifical intelligence grown in the last decade?","In a short sentence, what are your thoughts on the future of artificial intelligence?",]for prompt in prompts:API_RESPONSE= get_completion( [{"role": "user", "content": prompt}],model="gpt-3.5-turbo",logprobs=True, ) logprobs = [token.logprob for token inAPI_RESPONSE.choices[0].logprobs.content] response_text =API_RESPONSE.choices[0].message.content response_text_tokens = [token.token for token inAPI_RESPONSE.choices[0].logprobs.content] max_starter_length =max(len(s) for s in ["Prompt:", "Response:", "Tokens:", "Logprobs:", "Perplexity:"]) max_token_length =max(len(s) for s in response_text_tokens) formatted_response_tokens = [s.rjust(max_token_length) for s in response_text_tokens] formatted_lps = [f"{lp:.2f}".rjust(max_token_length) for lp in logprobs] perplexity_score = np.exp(-np.mean(logprobs))print("Prompt:".ljust(max_starter_length), prompt)print("Response:".ljust(max_starter_length), response_text, "\n")print("Tokens:".ljust(max_starter_length), " ".join(formatted_response_tokens))print("Logprobs:".ljust(max_starter_length), " ".join(formatted_lps))print("Perplexity:".ljust(max_starter_length), perplexity_score, "\n")
Prompt: In a short sentence, has artifical intelligence grown in the last decade?
Response: Yes, artificial intelligence has grown significantly in the last decade.
Tokens: Yes , artificial intelligence has grown significantly in the last decade .
Logprobs: -0.00 -0.00 -0.00 -0.00 -0.00 -0.53 -0.11 -0.00 -0.00 -0.01 -0.00 -0.00
Perplexity: 1.0564125277713383
Prompt: In a short sentence, what are your thoughts on the future of artificial intelligence?
Response: The future of artificial intelligence holds great potential for transforming industries and improving efficiency, but also raises ethical and societal concerns that must be carefully addressed.
Tokens: The future of artificial intelligence holds great potential for transforming industries and improving efficiency , but also raises ethical and societal concerns that must be carefully addressed .
Logprobs: -0.19 -0.03 -0.00 -0.00 -0.00 -0.30 -0.51 -0.24 -0.03 -1.45 -0.23 -0.03 -0.22 -0.83 -0.48 -0.01 -0.38 -0.07 -0.47 -0.63 -0.18 -0.26 -0.01 -0.14 -0.00 -0.59 -0.55 -0.00
Perplexity: 1.3220795252314004
In this example, gpt-3.5-turbo returned a lower perplexity score for a more deterministic question about recent history, and a higher perplexity score for a more speculative assessment about the near future. Again, while these differences don’t guarantee accuracy, they help point the way for our interpretation of the model’s results and our future use of them.
Nice! We were able to use the logprobs parameter to build a more robust classifier, evaluate our retrieval for Q&A system, and encode and decode each ‘byte’ of our tokens! logprobs adds useful information and signal to our completions output, and we are excited to see how developers incorporate it to improve applications.
Many developers think that having a critical bug in their code is the worst thing that can happen. Well, there is something much worse than that: Having a critical bug in your code and not knowing about it!
To make sure I get notified about critical bugs as soon as possible, I started looking for ways to find anomalies in my data. I quickly found that information about these subjects tend to get very complicated, and involve a lot of ad-hoc tools and dependencies.
I'm not a statistician and not a data scientist, I'm just a developer. Before I introduce dependencies into my system I make sure I really can't do without them. So, using some high school level statistics and a fair knowledge of SQL, I implemented a simple anomaly detection system that works.
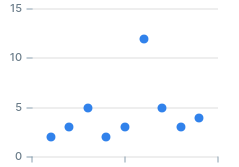
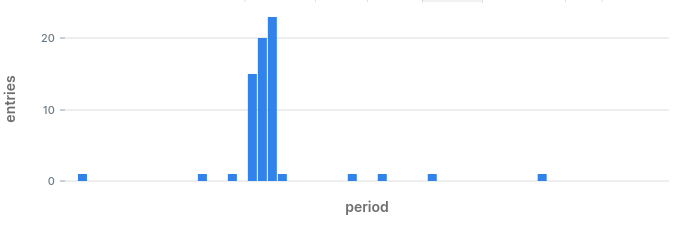
Anomaly in a data series is a significant deviation from some reasonable value. Looking at this series of numbers for example, which number stands out?
2, 3, 5, 2, 3, 12, 5, 3, 4
The number that stands out in this series is 12.
Scatter plot
This is intuitive to a human, but computer programs don't have intuition...
To find the anomaly in the series we first need to define what a reasonable value is, and then define how far away from this value we consider a significant deviation. A good place to start looking for a reasonable value is the mean:
SELECT avg(n)
FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n;
The range we defined is one standard deviation from the mean. Any value outside this range is considered an anomaly:
WITH series AS (
SELECT *
FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n
),
bounds AS (
SELECT
avg(n) - stddev(n) AS lower_bound,
avg(n) + stddev(n) AS upper_bound
FROM
series
)
SELECT
n,
n NOT BETWEEN lower_bound AND upper_bound AS is_anomaly
FROM
series,
bounds;
n │ is_anomaly
───┼────────────
2 │ f
3 │ f
5 │ f
2 │ f
3 │ f
12 │ t
5 │ f
3 │ f
4 │ f
Using the query we found that the value 12 is outside the range of acceptable values, and identified it as an anomaly.
Another way to represent a range of acceptable values is using a z-score. z-score, or Standard Score, is the number of standard deviations from the mean. In the previous section, our acceptable range was one standard deviation from the mean, or in other words, a z-score in the range ±1:
WITH series AS (
SELECT *
FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n
),
stats AS (
SELECT
avg(n) series_mean,
stddev(n) as series_stddev
FROM
series
)
SELECT
n,
(n - series_mean) / series_stddev as zscore
FROM
series,
stats;
Like before, we can detect anomalies by searching for values which are outside the acceptable range using the z-score:
WITH series AS (
SELECT *
FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n
),
stats AS (
SELECT
avg(n) series_avg,
stddev(n) as series_stddev
FROM
series
),
zscores AS (
SELECT
n,
(n - series_avg) / series_stddev AS zscore
FROM
series,
stats
)
SELECT
*,
zscore NOT BETWEEN -1 AND 1 AS is_anomaly
FROM
zscores;
n │ zscore │ is_anomaly
───┼─────────────────────────┼────────────
2 │ -0.75703329861022517346 │ f
3 │ -0.43259045634870009448 │ f
5 │ 0.21629522817435006346 │ f
2 │ -0.75703329861022517346 │ f
3 │ -0.43259045634870009448 │ f
12 │ 2.4873951240050256 │ t
5 │ 0.21629522817435006346 │ f
3 │ -0.43259045634870009448 │ f
4 │ -0.10814761408717501551 │ f
Using z-score, we also identified 12 as an anomaly in this series.
So far we used one standard deviation from the mean, or a z-score of ±1 to identify anomalies. Changing the z-score threshold can affect our results. For example, let’s see what anomalies we identify when the z-score is greater than 0.5 and when it’s greater than 3:
WITH series AS (
SELECT *
FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n
),
stats AS (
SELECT
avg(n) series_avg,
stddev(n) as series_stddev
FROM
series
),
zscores AS (
SELECT
n,
(n - series_avg) / series_stddev AS zscore
FROM
series,
stats
)
SELECT
*,
zscore NOT BETWEEN -0.5 AND 0.5 AS is_anomaly_0_5,
zscore NOT BETWEEN -1 AND 1 AS is_anomaly_1,
zscore NOT BETWEEN -3 AND 3 AS is_anomaly_3
FROM
zscores;
n │ zscore │ is_anomaly_0_5 │ is_anomaly_1 │ is_anomaly_3
───┼─────────────────────────┼────────────────┼──────────────┼──────────────
2 │ -0.75703329861022517346 │ t │ f │ f
3 │ -0.43259045634870009448 │ f │ f │ f
5 │ 0.21629522817435006346 │ f │ f │ f
2 │ -0.75703329861022517346 │ t │ f │ f
3 │ -0.43259045634870009448 │ f │ f │ f
12 │ 2.4873951240050256 │ t │ t │ f
5 │ 0.21629522817435006346 │ f │ f │ f
3 │ -0.43259045634870009448 │ f │ f │ f
4 │ -0.10814761408717501551 │ f │ f │ f
Let’s see what we got:
When we decreased the z-score threshold to 0.5, we identified the value 2 as an anomaly in addition to the value 12.
When we increased the z-score threshold to 3 we did not identify any anomaly.
The quality of our results are directly related to the parameters we set for the query. Later we’ll see how using backtesting can help us identify ideal values.
Application servers such as nginx, Apache and IIS write a lot of useful information to access logs. The data in these logs can be extremely useful in identifying anomalies.
We are going to analyze logs of a web application, so the data we are most interested in is the timestamp and the status code of every response from the server. To illustrate the type of insight we can draw from just this data:
A sudden increase in 500 status code: You may have a problem in the server. Did you just push a new version? Is there an external service you’re using that started failing in unexpected ways?
A sudden increase in 400 status code: You may have a problem in the client. Did you change some validation logic and forgot to update the client? Did you make a change and forgot to handle backward compatibility?
A sudden increase in 404 status code: You may have an SEO problem. Did you move some pages and forgot to set up redirects? Is there some script kiddy running a scan on your site?
A sudden increase in 200 status code: You either have some significant legit traffic coming in, or you are under a DOS attack. Either way, you probably want to check where it’s coming from.
Parsing and processing logs is outside the scope of this article, so let’s assume we did that and we have a table that looks like this:
CREATE TABLE server_log_summary AS (
period timestamptz,
status_code int,
entries int
);
The table stores the number of entries for each status code at a given period. For example, our table stores how many responses returned each status code every minute:
db=# SELECT * FROM server_log_summary ORDER BY period DESC LIMIT 10;
Note that the table has a row for every minute, even if the status code was never returned in that minute. Given a table of statuses, it’s very tempting to do something like this:
– Wrong!
SELECT
date_trunc(‘minute’, timestamp) AS period,
status_code,
count() AS entries
FROM
server_log
GROUP BY
period,
status_code;
This is a common mistake and it can leave you with gaps in the data. Zero is a value, and it holds a significant meaning. A better approach is to create an “axis”, and join to it:
– Correct!
WITH axis AS (
SELECT
status_code,
generate_series(
date_trunc(‘minute’, now()),
date_trunc(‘minute’, now() - interval ‘1 hour’),
interval ‘1 minute’ * -1
) AS period
FROM (
VALUES (200), (400), (404), (500)
) AS t(status_code)
)
SELECT
a.period,
a.status_code,
count() AS entries
FROM
axis a
LEFT JOIN server_log l ON (
date_trunc(‘minute’, l.timestamp) = a.period
AND l.status_code = a.status_code
)
GROUP BY
period,
status_code;
First we generate an axis using a cartesian join between the status codes we want to track, and the times we want to monitor. To generate the axis we used two nice features of PostgreSQL:
VALUES list: special clause that can generate “constant tables”, as the documentation calls it. You might be familiar with the VALUES clause from INSERT statements. In the old days, to generate data we had to use a bunch of SELECT … UNION ALL… using VALUES is much nicer.
After generating the axis, we left join the actual data into it to get a complete series for each status code. The resulting data has no gaps, and is ready for analysis.
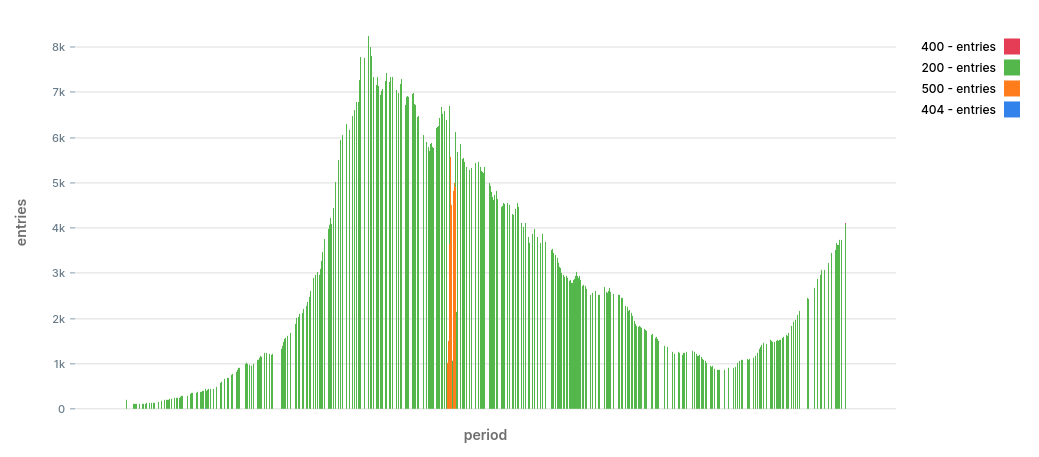
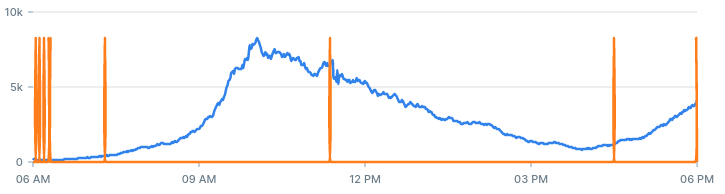
To get a sense of the data, let’s draw a stacked bar chart by status:
stacked bar chart by status, over time
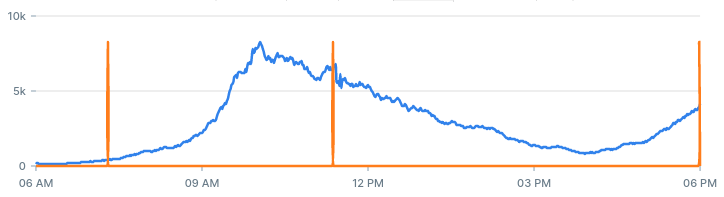
The chart shows a period of 12 hours. It looks like we have a nice trend with two peaks at around 09:30 and again at 18:00.
We also spot right away that at ~11:30 there was a significant increase in 500 errors. The burst died down after around 10 minutes. This is the type of anomalies we want to identify early on.
It’s entirely possible that there were other problems during that time, we just can’t spot them with a naked eye.
In anomaly detection systems, we usually want to identify if we have an anomaly right now, and send an alert.
To identify if the last datapoint is an anomaly, we start by calculating the mean and standard deviation for each status code in the past hour:
db=# WITH stats AS (
SELECT
status_code,
(MAX(ARRAY[EXTRACT(‘epoch’ FROM period), entries]))[2] AS last_value,
AVG(entries) AS mean_entries,
STDDEV(entries) AS stddev_entries
FROM
server_log_summary
WHERE
– In the demo data use:
– period > ‘2020-08-01 17:00 UTC’::timestamptz
period > now() - interval ‘1 hour’
GROUP BY
status_code
)
SELECT * FROM stats;
To get the last value in a GROUP BY in addition to the mean and standard deviation we used a little array trick.
Next, we calculate the z-score for the last value for each status code:
db=# WITH stats AS (
SELECT
status_code,
(MAX(ARRAY[EXTRACT(‘epoch’ FROM period), entries]))[2] AS last_value,
AVG(entries) AS mean_entries,
STDDEV(entries) AS stddev_entries
FROM
server_log_summary
WHERE
– In the demo data use:
– period > ‘2020-08-01 17:00 UTC’::timestamptz
period > now() - interval ‘1 hour’
GROUP BY
status_code
)
SELECT
*,
(last_value - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore
FROM
stats;
We calculated the z-score by finding the number of standard deviations between the last value and the mean. To avoid a “division by zero” error we transform the denominator to NULL if it’s zero.
Looking at the z-scores we got, we can spot that status code 400 got a very high z-score of 6. In the past minute we returned a 400 status code 24 times, which is significantly higher than the average of 0.73 in the past hour.
Let’s take a look at the raw data:
SELECT *
FROM server_log_summary
WHERE status_code = 400
ORDER BY period DESC
LIMIT 20;
In the previous section we identified an anomaly. We found an increase in 400 status code because the z-score was 6. But how do we set the threshold for the z-score? Is a z-score of 3 an anomaly? What about 2, or 1?
To find thresholds that fit our needs, we can run simulations on past data with different values, and evaluate the results. This is often called backtesting.
The first thing we need to do is to calculate the mean and the standard deviation for each status code up until every row, just as if it’s the current value. This is a classic job for a window function:
WITH calculations_over_window AS (
SELECT
status_code,
period,
entries,
AVG(entries) OVER status_window as mean_entries,
STDDEV(entries) OVER status_window as stddev_entries
FROM
server_log_summary
WINDOW status_window AS (
PARTITION BY status_code
ORDER BY period
ROWS BETWEEN 60 PRECEDING AND CURRENT ROW
)
)
SELECT *
FROM calculations_over_window
ORDER BY period DESC
LIMIT 20;
To calculate the mean and standard deviation over a sliding window of 60 minutes, we use a window function. To avoid having to repeat the WINDOW clause for every aggregate, we define a named window called “status_window”. This is another nice feature of PostgreSQL.
In the results we can now see that for every entry, we have the mean and standard deviation of the previous 60 rows. This is similar to the calculation we did in the previous section, only this time we do it for every row.
Now we can calculate the z-score for every row:
WITH calculations_over_window AS (
SELECT
status_code,
period,
entries,
AVG(entries) OVER status_window as mean_entries,
STDDEV(entries) OVER status_window as stddev_entries
FROM
server_log_summary
WINDOW status_window AS (
PARTITION BY status_code
ORDER BY period
ROWS BETWEEN 60 PRECEDING AND CURRENT ROW
)
),
with_zscore AS (
SELECT
*,
(entries - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore
FROM
calculations_over_window
)
SELECT
status_code,
period,
zscore
FROM
with_zscore
ORDER BY
period DESC
LIMIT
20;
We now have z-scores for every row, and we can try to identify anomalies:
WITH calculations_over_window AS (
SELECT
status_code,
period,
entries,
AVG(entries) OVER status_window as mean_entries,
STDDEV(entries) OVER status_window as stddev_entries
FROM
server_log_summary
WINDOW status_window AS (
PARTITION BY status_code
ORDER BY period
ROWS BETWEEN 60 PRECEDING AND CURRENT ROW
)
),
with_zscore AS (
SELECT
*,
(entries - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore
FROM
calculations_over_window
),
with_alert AS (
SELECT
*,
zscore > 3 AS alert
FROM
with_zscore
)
SELECT
status_code,
period,
entries,
zscore,
alert
FROM
with_alert
WHERE
alert
ORDER BY
period DESC
LIMIT
20;
status_code │ period │ entries │ zscore │ alert
────────────┼────────────────────────┼─────────┼────────────────────┼───────
400 │ 2020-08-01 18:00:00+00 │ 24 │ 6.823777205473068 │ t
400 │ 2020-08-01 17:59:00+00 │ 12 │ 7.445849602151508 │ t
400 │ 2020-08-01 17:58:00+00 │ 2 │ 4.838594613958412 │ t
500 │ 2020-08-01 17:29:00+00 │ 1 │ 3.0027309973793774 │ t
500 │ 2020-08-01 17:20:00+00 │ 1 │ 3.3190952747131184 │ t
500 │ 2020-08-01 17:18:00+00 │ 1 │ 3.7438474117708043 │ t
500 │ 2020-08-01 17:13:00+00 │ 1 │ 3.7438474117708043 │ t
500 │ 2020-08-01 17:09:00+00 │ 1 │ 4.360778994930029 │ t
500 │ 2020-08-01 16:59:00+00 │ 1 │ 3.7438474117708043 │ t
400 │ 2020-08-01 16:29:00+00 │ 1 │ 3.0027309973793774 │ t
404 │ 2020-08-01 16:13:00+00 │ 1 │ 3.0027309973793774 │ t
500 │ 2020-08-01 15:13:00+00 │ 1 │ 3.0027309973793774 │ t
500 │ 2020-08-01 15:11:00+00 │ 1 │ 3.0027309973793774 │ t
500 │ 2020-08-01 14:58:00+00 │ 1 │ 3.0027309973793774 │ t
400 │ 2020-08-01 14:56:00+00 │ 1 │ 3.0027309973793774 │ t
400 │ 2020-08-01 14:55:00+00 │ 1 │ 3.3190952747131184 │ t
400 │ 2020-08-01 14:50:00+00 │ 1 │ 3.3190952747131184 │ t
500 │ 2020-08-01 14:37:00+00 │ 1 │ 3.0027309973793774 │ t
400 │ 2020-08-01 14:35:00+00 │ 1 │ 3.3190952747131184 │ t
400 │ 2020-08-01 14:32:00+00 │ 1 │ 3.3190952747131184 │ t
We decided to classify values with z-score greater than 3 as anomalies. 3 is usually the magic number you’ll see in textbooks, but don’t get sentimental about it because you can definitely change it to get better results.
In the last query we detected a large number of “anomalies” with just one entry. This is very common in errors that don’t happen very often. In our case, every once in a while we get a 400 status code, but because it doesn’t happen very often, the standard deviation is very low so that even a single error can be considered way above the acceptable value.
We don’t really want to receive an alert in the middle of the night just because of one 400 status code. We can’t have every curious developer fiddling with the devtools in his browser wake us up in the middle of the night.
To eliminate rows with only a few entries we set a threshold:
WITH calculations_over_window AS (
SELECT
status_code,
period,
entries,
AVG(entries) OVER status_window as mean_entries,
STDDEV(entries) OVER status_window as stddev_entries
FROM
server_log_summary
WINDOW status_window AS (
PARTITION BY status_code
ORDER BY period
ROWS BETWEEN 60 PRECEDING AND CURRENT ROW
)
),
with_zscore AS (
SELECT
*,
(entries - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore
FROM
calculations_over_window
),
with_alert AS (
SELECT
*,
entries > 10 AND zscore > 3 AS alert
FROM
with_zscore
)
SELECT
status_code,
period,
entries,
zscore,
alert
FROM
with_alert
WHERE
alert
ORDER BY
period DESC;
status_code │ period │ entries │ zscore │ alert
────────────┼────────────────────────┼─────────┼────────────────────┼───────
400 │ 2020-08-01 18:00:00+00 │ 24 │ 6.823777205473068 │ t
400 │ 2020-08-01 17:59:00+00 │ 12 │ 7.445849602151508 │ t
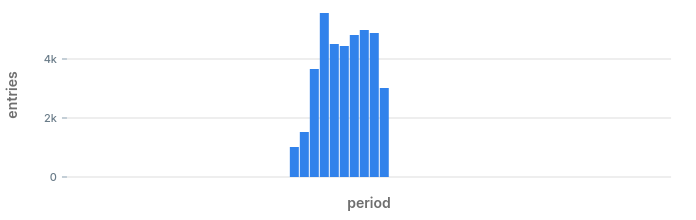
500 │ 2020-08-01 11:29:00+00 │ 5001 │ 3.172198441961645 │ t
500 │ 2020-08-01 11:28:00+00 │ 4812 │ 3.3971646910263917 │ t
500 │ 2020-08-01 11:27:00+00 │ 4443 │ 3.5349400089601586 │ t
500 │ 2020-08-01 11:26:00+00 │ 4522 │ 4.1264785335553595 │ t
500 │ 2020-08-01 11:25:00+00 │ 5567 │ 6.17629336121081 │ t
500 │ 2020-08-01 11:24:00+00 │ 3657 │ 6.8689992361141154 │ t
500 │ 2020-08-01 11:23:00+00 │ 1512 │ 6.342260662589681 │ t
500 │ 2020-08-01 11:22:00+00 │ 1022 │ 7.682189672504754 │ t
404 │ 2020-08-01 07:20:00+00 │ 23 │ 5.142126410098476 │ t
404 │ 2020-08-01 07:19:00+00 │ 20 │ 6.091200697920824 │ t
404 │ 2020-08-01 07:18:00+00 │ 15 │ 7.57547172423804 │ t
After eliminating potential anomalies with less than 10 entries we get much fewer, and probably more relevant results.
In the previous section we eliminated potential anomalies with less than 10 entries. Using thresholds we were able to remove some non interesting anomalies.
Let’s have a look at the data for status code 400 after applying the threshold:
status_code │ period │ entries │ zscore │ alert
────────────┼────────────────────────┼─────────┼────────────────────┼───────
400 │ 2020-08-01 18:00:00+00 │ 24 │ 6.823777205473068 │ t
400 │ 2020-08-01 17:59:00+00 │ 12 │ 7.445849602151508 │ t
The first alert happened in 17:59, and a minute later the z-score was still high with a large number of entries and so we classified the next rows at 18:00 as an anomaly as well.
If you think of an alerting system, we want to send an alert only when an anomaly first happens. We don’t want to send an alert every minute until the z-score comes back below the threshold. In this case, we only want to send one alert at 17:59. We don’t want to send another alert a minute later at 18:00.
Let’s remove alerts where the previous period was also classified as an alert:
WITH calculations_over_window AS (
SELECT
status_code,
period,
entries,
AVG(entries) OVER status_window as mean_entries,
STDDEV(entries) OVER status_window as stddev_entries
FROM
server_log_summary
WINDOW status_window AS (
PARTITION BY status_code
ORDER BY period
ROWS BETWEEN 60 PRECEDING AND CURRENT ROW
)
),
with_zscore AS (
SELECT
*,
(entries - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore
FROM
calculations_over_window
),
with_alert AS (
SELECT
*,
entries > 10 AND zscore > 3 AS alert
FROM
with_zscore
),
with_previous_alert AS (
SELECT
*,
LAG(alert) OVER (PARTITION BY status_code ORDER BY period) AS previous_alert
FROM
with_alert
)
SELECT
status_code,
period,
entries,
zscore,
alert
FROM
with_previous_alert
WHERE
alert AND NOT previous_alert
ORDER BY
period DESC;
status_code │ period │ entries │ zscore │ alert
────────────┼────────────────────────┼─────────┼───────────────────┼───────
400 │ 2020-08-01 17:59:00+00 │ 12 │ 7.445849602151508 │ t
500 │ 2020-08-01 11:22:00+00 │ 1022 │ 7.682189672504754 │ t
404 │ 2020-08-01 07:18:00+00 │ 15 │ 7.57547172423804 │ t
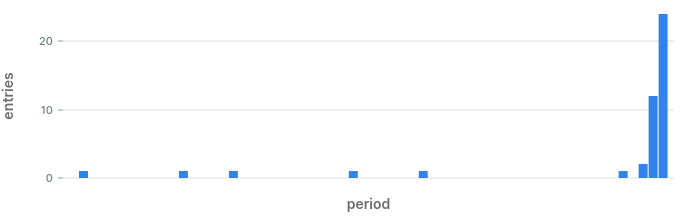
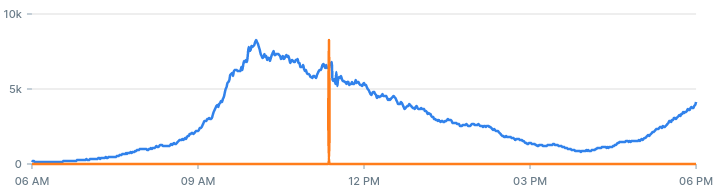
By eliminating alerts that were already triggered we get a very small list of anomalies that may have happened during the day. Looking at the results we can see what anomalies we would have discovered:
Anomaly in status code 400 at 17:59: we also found that one earlier.
Anomaly in status code 400
Anomaly in status code 500: we spotted this one on the chart when we started.
Anomaly in status code 500
Anomaly in status code 404: this is a hidden hidden anomaly which we did not know about until now.
A hidden anomaly in status code 404
The query can now be used to fire alerts when it encounters an anomaly.
To get a sense of each parameter, let’s adjust the values and see how it affects the number and quality of alerts we get.
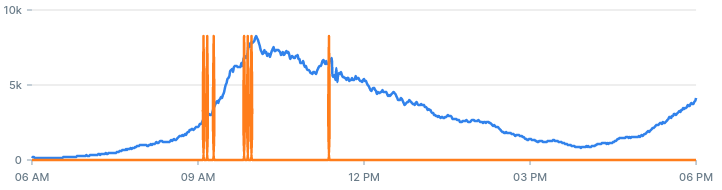
If we decrease the value of the z-score threshold from 3 to 1, we should get more alerts. With a lower threshold, more values are likely to be considered an anomaly:
Backtesting with lower z-score threshold
If we increase the entries threshold from 10 to 30, we should get less alerts:
Backtesting with higher entries threshold
If we increase the backtest period from 60 minutes to 360 minutes, we get more alerts:
Backtesting with higher entries threshold
A good alerting system is a system that produces true alerts, at a reasonable time. Using the backtesting query you can experiment with different values that produces quality alerts you can act on.
Using a z-score for detecting anomalies is an easy way to get started with anomaly detection and see results right away. But, this method is not always the best choice, and if you don’t get good alerts using this method, there are some improvements and other methods you can try using just SQL.
Our system uses a mean to determine a reasonable value, and a lookback period to determine how long back to calculate that mean over. In our case, we calculated the mean based on data from 1 hour ago.
Using this method of calculating mean gives the same weight to entries that happened 1 hour ago and to entries that just happened. If you give more weight to recent entries at the expense of previous entries, the new weighted mean should become more sensitive to recent entries, and you may be able to identify anomalies quicker.
To give more weight to recent entries, you can use a weighted average:
SELECT
status_code,
avg(entries) as mean,
sum(
entries *
(60 - extract(‘seconds’ from ‘2020-08-01 17:00 UTC’::timestamptz - period))
) / (60 * 61 / 2) as weighted_mean
FROM
server_log_summary
WHERE
– Last 60 periods
period > ‘2020-08-01 17:00 UTC’::timestamptz
GROUP BY
status_code;
In the results you can see the difference between the mean and the weighted mean for each status code.
A weighted average is a very common indicator used by stock traders. We used a linear weighted average, but there are also exponential weighted averages and others you can try.
In statistics, a mean is considered not robust because it is influenced by extreme values. Given our use case, the measure we are using to identify extreme values, is affected by those values we are trying to identify.
For example, in the beginning of the article we used this series of values:
2, 3, 5, 2, 3, 12, 5, 3, 4
The mean of this series is 4.33, and we detected 12 as an anomaly.
If the 12 were a 120, the mean of the series would have been 16.33. Hence, our “reasonable” value is heavily affected by the values it is supposed to identify.
A measure that is considered more robust is a median. The median of a series is the value that half the series is greater than, and half the series is less than:
SELECT percentile_disc(0.5) within group(order by n)
FROM unnest(ARRAY[2, 3, 5, 2, 3, 120, 5, 3, 4]) as n;
median
────────
3
To calculate the median in PostgreSQL we use the function percentile_disc. In the series above, the median is 3. If we sort the list and cut it in the middle it will become more clear:
2, 2, 3, 3, 3
4, 5, 5, 12
If we change the value of 12 to 120, the median will not be affected at all:
2, 2, 3, 3, 3
4, 5, 5, 120
This is why a median is considered more robust than mean.
Median absolute deviation (MAD) is another way of finding anomalies in a series. MAD is considered better than z-score for real life data.
MAD is calculated by finding the median of the deviations from the series median. Just for comparison, the standard deviation is the root square of the average square distance from the mean.
We used the number of entries per minute as an indicator. However, depending on the use case, there might be other things you can measure that can yield better results. For example:
To try and identify DOS attacks you can monitor the ratio between unique IP addresses to HTTP requests.
To reduce the amount of false positives, you can normalize the number of responses to the proportion of the total responses. This way, for example, if you’re using a flaky remote service that fails once after every certain amount of requests, using the proportion may not trigger an alert when the increase in errors correlates with an increase in overall traffic.
The method presented above is a very simple method to detect anomalies and produce actionable alerts that can potentially save you a lot of grief. There are many tools out there that provide similar functionally, but they require either tight integration or $$$. The main appeal of this approach is that you can get started with tools you probably already have, some SQL and a scheduled task!
UPDATE: many readers asked me how I created the charts in this article… well, I used PopSQL. It’s a new modern SQL editor focused on collaborative editing. If you’re in the market for one, go check it out.
Tembo improves the developer experience of deploying, managing, and scaling Postgres. Tembo is under active development and you are free to use anything we have open-sourced.
Why Postgres?
Postgres is the best OSS database in the world, with millions of active deployments, growing faster than MySQL. It is battle-tested with a large community that can handle SQL (relational) and JSON (non-relational) queries and a wide range of workloads (analytical, time-series, geospatial, etc.), through its rich ecosystem of add-ons and extensions.
Omakub is a practical tool designed to simplify the process of setting up development environments on Linux systems. Drawing inspiration from DHH’s (David Heinemeier Hansson) approach to development, Omakub focuses on reducing the complexities of configuration while offering a streamlined solution for developers.
What's included in? Git is one of the essential tools included in Omakub, allowing developers to easily manage version control. The setup process is straightforward, ensuring a quick start without needing extensive manual configuration.
For container management, Omakub uses Docker, providing a hassle-free way to set up and run containers. This ensures that applications can be isolated from the host environment and dependencies are managed effectively.
Omakub also supports Neovim and VSCode as text editors, catering to different preferences among developers. Both editors are pre-configured to enhance productivity, allowing users to start coding with minimal setup effort.
The shell environment is optimized with Zsh and Fish, offering customizable and efficient workflows. Omakub provides a clear configuration for these shells, improving command-line experiences for developers who prefer either option.
Zellij is another tool included, designed for terminal multiplexing. It enables developers to manage multiple terminal sessions within a single window, making it easier to work across different projects or tasks simultaneously.
Overall, Omakub provides a balanced, practical approach to development setups on Linux. It offers a solid range of tools that are configured to get developers up and running quickly without unnecessary complexity.
The secret sauce of almost every white-label SaaS is Caddy's original On-Demand TLS feature. Grow your SaaS business by orders of magnitude with ease!
Dynamically provision certificates
With On-Demand TLS, only Caddy obtains, renews, and maintains certificates on-the-fly during TLS handshakes. Perfect for customer-owned domains.
Massively scale your TLS
Other web servers and scripted certificate tools fall over with hundreds of thousands of sites or thousands of instances. Caddy is designed to manage certificates reliably at this scale.

{kind=link}