Simple Anomaly Detection Using Plain SQL | Haki Benita
From the collection
Best Development Tools & Libraries
To follow along with the article and experiment with actual data online check out the interactive editor on PopSQL ≫
2, 3, 5, 2, 3, 12, 5, 3, 4
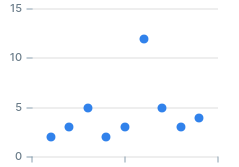
SELECT avg(n) FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n;──────────────────── 4.3333333333333333
SELECT stddev(n) FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n;──────────────────── 3.0822070014844882
SELECT avg(n) - stddev(n) AS lower_bound, avg(n) + stddev(n) AS upper_bound FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n;───────────────────┼──────────────────── 1.2511263318488451 │ 7.4155403348178215
WITH series AS ( SELECT * FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n ), bounds AS ( SELECT avg(n) - stddev(n) AS lower_bound, avg(n) + stddev(n) AS upper_bound FROM series ) SELECT n, n NOT BETWEEN lower_bound AND upper_bound AS is_anomaly FROM series, bounds;n │ is_anomaly ───┼──────────── 2 │ f 3 │ f 5 │ f 2 │ f 3 │ f 12 │ t 5 │ f 3 │ f 4 │ f
WITH series AS ( SELECT * FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n ), stats AS ( SELECT avg(n) series_mean, stddev(n) as series_stddev FROM series ) SELECT n, (n - series_mean) / series_stddev as zscore FROM series, stats;n │ zscore ───┼───────────────────────── 2 │ -0.75703329861022517346 3 │ -0.43259045634870009448 5 │ 0.21629522817435006346 2 │ -0.75703329861022517346 3 │ -0.43259045634870009448 12 │ 2.4873951240050256 5 │ 0.21629522817435006346 3 │ -0.43259045634870009448 4 │ -0.10814761408717501551
WITH series AS ( SELECT * FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n ), stats AS ( SELECT avg(n) series_avg, stddev(n) as series_stddev FROM series ), zscores AS ( SELECT n, (n - series_avg) / series_stddev AS zscore FROM series, stats ) SELECT *, zscore NOT BETWEEN -1 AND 1 AS is_anomaly FROM zscores;n │ zscore │ is_anomaly ───┼─────────────────────────┼──────────── 2 │ -0.75703329861022517346 │ f 3 │ -0.43259045634870009448 │ f 5 │ 0.21629522817435006346 │ f 2 │ -0.75703329861022517346 │ f 3 │ -0.43259045634870009448 │ f 12 │ 2.4873951240050256 │ t 5 │ 0.21629522817435006346 │ f 3 │ -0.43259045634870009448 │ f 4 │ -0.10814761408717501551 │ f
WITH series AS ( SELECT * FROM unnest(array[2, 3, 5, 2, 3, 12, 5, 3, 4]) AS n ), stats AS ( SELECT avg(n) series_avg, stddev(n) as series_stddev FROM series ), zscores AS ( SELECT n, (n - series_avg) / series_stddev AS zscore FROM series, stats ) SELECT *, zscore NOT BETWEEN -0.5 AND 0.5 AS is_anomaly_0_5, zscore NOT BETWEEN -1 AND 1 AS is_anomaly_1, zscore NOT BETWEEN -3 AND 3 AS is_anomaly_3 FROM zscores;n │ zscore │ is_anomaly_0_5 │ is_anomaly_1 │ is_anomaly_3 ───┼─────────────────────────┼────────────────┼──────────────┼────────────── 2 │ -0.75703329861022517346 │ t │ f │ f 3 │ -0.43259045634870009448 │ f │ f │ f 5 │ 0.21629522817435006346 │ f │ f │ f 2 │ -0.75703329861022517346 │ t │ f │ f 3 │ -0.43259045634870009448 │ f │ f │ f 12 │ 2.4873951240050256 │ t │ t │ f 5 │ 0.21629522817435006346 │ f │ f │ f 3 │ -0.43259045634870009448 │ f │ f │ f 4 │ -0.10814761408717501551 │ f │ f │ f
- When we decreased the z-score threshold to 0.5, we identified the value 2 as an anomaly in addition to the value 12.
- When we increased the z-score threshold to 3 we did not identify any anomaly.
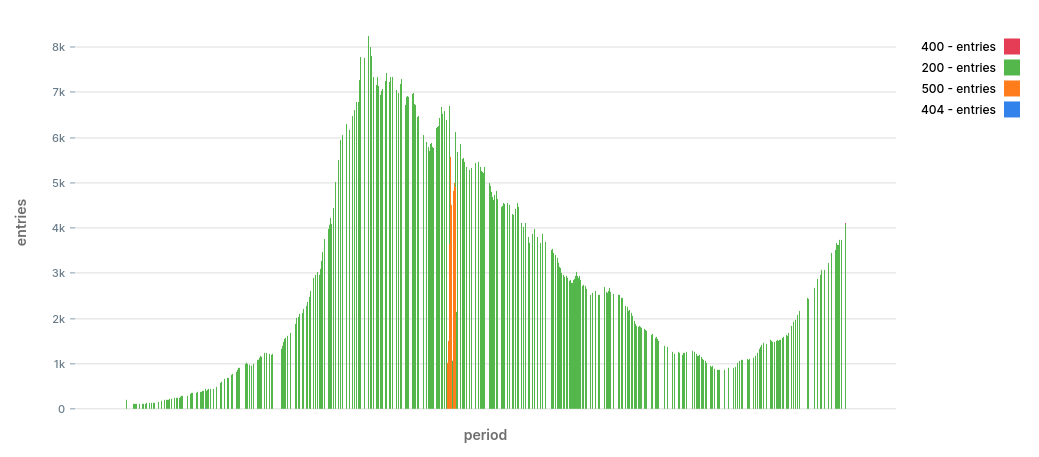
- A sudden increase in 500 status code: You may have a problem in the server. Did you just push a new version? Is there an external service you’re using that started failing in unexpected ways?
- A sudden increase in 400 status code: You may have a problem in the client. Did you change some validation logic and forgot to update the client? Did you make a change and forgot to handle backward compatibility?
- A sudden increase in 404 status code: You may have an SEO problem. Did you move some pages and forgot to set up redirects? Is there some script kiddy running a scan on your site?
- A sudden increase in 200 status code: You either have some significant legit traffic coming in, or you are under a DOS attack. Either way, you probably want to check where it’s coming from.
CREATE TABLE server_log_summary AS ( period timestamptz, status_code int, entries int );
db=# SELECT * FROM server_log_summary ORDER BY period DESC LIMIT 10;───────────────────────┼─────────────┼───────── 2020-08-01 18:00:00+00 │ 200 │ 4084 2020-08-01 18:00:00+00 │ 404 │ 0 2020-08-01 18:00:00+00 │ 400 │ 24 2020-08-01 18:00:00+00 │ 500 │ 0 2020-08-01 17:59:00+00 │ 400 │ 12 2020-08-01 17:59:00+00 │ 200 │ 3927 2020-08-01 17:59:00+00 │ 500 │ 0 2020-08-01 17:59:00+00 │ 404 │ 0 2020-08-01 17:58:00+00 │ 400 │ 2 2020-08-01 17:58:00+00 │ 200 │ 3850
– Wrong! SELECT date_trunc(‘minute’, timestamp) AS period, status_code, count() AS entries FROM server_log GROUP BY period, status_code;
– Correct! WITH axis AS ( SELECT status_code, generate_series( date_trunc(‘minute’, now()), date_trunc(‘minute’, now() - interval ‘1 hour’), interval ‘1 minute’ * -1 ) AS period FROM ( VALUES (200), (400), (404), (500) ) AS t(status_code) ) SELECT a.period, a.status_code, count() AS entries FROM axis a LEFT JOIN server_log l ON ( date_trunc(‘minute’, l.timestamp) = a.period AND l.status_code = a.status_code ) GROUP BY period, status_code;
- generate_series: function that generates a range of values.
- VALUES list: special clause that can generate “constant tables”, as the documentation calls it. You might be familiar with the VALUES clause from INSERT statements. In the old days, to generate data we had to use a bunch of SELECT … UNION ALL… using VALUES is much nicer.
db=# WITH stats AS ( SELECT status_code, (MAX(ARRAY[EXTRACT(‘epoch’ FROM period), entries]))[2] AS last_value, AVG(entries) AS mean_entries, STDDEV(entries) AS stddev_entries FROM server_log_summary WHERE – In the demo data use: – period > ‘2020-08-01 17:00 UTC’::timestamptz period > now() - interval ‘1 hour’ GROUP BY status_code ) SELECT * FROM stats;status_code │ last_value │ mean_entries │ stddev_entries ────────────┼────────────┼────────────────────────┼──────────────────────── 404 │ 0 │ 0.13333333333333333333 │ 0.34280333180088158345 500 │ 0 │ 0.15000000000000000000 │ 0.36008473579027553993 200 │ 4084 │ 2779.1000000000000000 │ 689.219644702665 400 │ 24 │ 0.73333333333333333333 │ 3.4388935285299212
db=# WITH stats AS ( SELECT status_code, (MAX(ARRAY[EXTRACT(‘epoch’ FROM period), entries]))[2] AS last_value, AVG(entries) AS mean_entries, STDDEV(entries) AS stddev_entries FROM server_log_summary WHERE – In the demo data use: – period > ‘2020-08-01 17:00 UTC’::timestamptz period > now() - interval ‘1 hour’ GROUP BY status_code ) SELECT *, (last_value - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore FROM stats;status_code │ last_value │ mean_entries │ stddev_entries │ zscore ────────────┼────────────┼──────────────┼────────────────┼──────── 404 │ 0 │ 0.133 │ 0.3428 │ -0.388 500 │ 0 │ 0.150 │ 0.3600 │ -0.416 200 │ 4084 │ 2779.100 │ 689.2196 │ 1.893 400 │ 24 │ 0.733 │ 3.4388 │ 6.765
SELECT * FROM server_log_summary WHERE status_code = 400 ORDER BY period DESC LIMIT 20;───────────────────────┼─────────────┼───────── 2020-08-01 18:00:00+00 │ 400 │ 24 2020-08-01 17:59:00+00 │ 400 │ 12 2020-08-01 17:58:00+00 │ 400 │ 2 2020-08-01 17:57:00+00 │ 400 │ 0 2020-08-01 17:56:00+00 │ 400 │ 1 2020-08-01 17:55:00+00 │ 400 │ 0 2020-08-01 17:54:00+00 │ 400 │ 0 2020-08-01 17:53:00+00 │ 400 │ 0 2020-08-01 17:52:00+00 │ 400 │ 0 2020-08-01 17:51:00+00 │ 400 │ 0 2020-08-01 17:50:00+00 │ 400 │ 0 2020-08-01 17:49:00+00 │ 400 │ 0 2020-08-01 17:48:00+00 │ 400 │ 0 2020-08-01 17:47:00+00 │ 400 │ 0 2020-08-01 17:46:00+00 │ 400 │ 0 2020-08-01 17:45:00+00 │ 400 │ 0 2020-08-01 17:44:00+00 │ 400 │ 0 2020-08-01 17:43:00+00 │ 400 │ 0 2020-08-01 17:42:00+00 │ 400 │ 0 2020-08-01 17:41:00+00 │ 400 │ 0
WITH calculations_over_window AS ( SELECT status_code, period, entries, AVG(entries) OVER status_window as mean_entries, STDDEV(entries) OVER status_window as stddev_entries FROM server_log_summary WINDOW status_window AS ( PARTITION BY status_code ORDER BY period ROWS BETWEEN 60 PRECEDING AND CURRENT ROW ) ) SELECT * FROM calculations_over_window ORDER BY period DESC LIMIT 20;status_code │ period │ entries │ mean_entries │ stddev_entries ────────────┼────────────────────────┼─────────┼────────────────────────┼──────────────────────── 200 │ 2020-08-01 18:00:00+00 │ 4084 │ 2759.9672131147540984 │ 699.597407256800 400 │ 2020-08-01 18:00:00+00 │ 24 │ 0.72131147540983606557 │ 3.4114080550460080 404 │ 2020-08-01 18:00:00+00 │ 0 │ 0.13114754098360655738 │ 0.34036303344446665347 500 │ 2020-08-01 18:00:00+00 │ 0 │ 0.14754098360655737705 │ 0.35758754516763638735 500 │ 2020-08-01 17:59:00+00 │ 0 │ 0.16393442622950819672 │ 0.37328844382740000274 400 │ 2020-08-01 17:59:00+00 │ 12 │ 0.32786885245901639344 │ 1.5676023249473471 200 │ 2020-08-01 17:59:00+00 │ 3927 │ 2718.6721311475409836 │ 694.466863171826 404 │ 2020-08-01 17:59:00+00 │ 0 │ 0.13114754098360655738 │ 0.34036303344446665347 500 │ 2020-08-01 17:58:00+00 │ 0 │ 0.16393442622950819672 │ 0.37328844382740000274 404 │ 2020-08-01 17:58:00+00 │ 0 │ 0.13114754098360655738 │ 0.34036303344446665347 200 │ 2020-08-01 17:58:00+00 │ 3850 │ 2680.4754098360655738 │ 690.967283512936 400 │ 2020-08-01 17:58:00+00 │ 2 │ 0.13114754098360655738 │ 0.38623869286861001780 404 │ 2020-08-01 17:57:00+00 │ 0 │ 0.13114754098360655738 │ 0.34036303344446665347 400 │ 2020-08-01 17:57:00+00 │ 0 │ 0.09836065573770491803 │ 0.30027309973793774423 500 │ 2020-08-01 17:57:00+00 │ 1 │ 0.16393442622950819672 │ 0.37328844382740000274 200 │ 2020-08-01 17:57:00+00 │ 3702 │ 2643.0327868852459016 │ 688.414796645480 200 │ 2020-08-01 17:56:00+00 │ 3739 │ 2607.5081967213114754 │ 688.769908918569 404 │ 2020-08-01 17:56:00+00 │ 0 │ 0.14754098360655737705 │ 0.35758754516763638735 400 │ 2020-08-01 17:56:00+00 │ 1 │ 0.11475409836065573770 │ 0.32137001808599097120 500 │ 2020-08-01 17:56:00+00 │ 0 │ 0.14754098360655737705 │ 0.35758754516763638735
WITH calculations_over_window AS ( SELECT status_code, period, entries, AVG(entries) OVER status_window as mean_entries, STDDEV(entries) OVER status_window as stddev_entries FROM server_log_summary WINDOW status_window AS ( PARTITION BY status_code ORDER BY period ROWS BETWEEN 60 PRECEDING AND CURRENT ROW ) ),with_zscore AS ( SELECT *, (entries - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore FROM calculations_over_window )
SELECT status_code, period, zscore FROM with_zscore ORDER BY period DESC LIMIT 20;
status_code │ period │ zscore ────────────┼────────────────────────┼────────────────────── 200 │ 2020-08-01 18:00:00+00 │ 1.8925638848161648 400 │ 2020-08-01 18:00:00+00 │ 6.823777205473068 404 │ 2020-08-01 18:00:00+00 │ -0.38531664163524526 500 │ 2020-08-01 18:00:00+00 │ -0.41260101365496504 500 │ 2020-08-01 17:59:00+00 │ -0.4391628750910588 400 │ 2020-08-01 17:59:00+00 │ 7.445849602151508 200 │ 2020-08-01 17:59:00+00 │ 1.7399359608515874 404 │ 2020-08-01 17:59:00+00 │ -0.38531664163524526 500 │ 2020-08-01 17:58:00+00 │ -0.4391628750910588 404 │ 2020-08-01 17:58:00+00 │ -0.38531664163524526 200 │ 2020-08-01 17:58:00+00 │ 1.6925903990967166 400 │ 2020-08-01 17:58:00+00 │ 4.838594613958412 404 │ 2020-08-01 17:57:00+00 │ -0.38531664163524526 400 │ 2020-08-01 17:57:00+00 │ -0.32757065425956844 500 │ 2020-08-01 17:57:00+00 │ 2.2397306629644 200 │ 2020-08-01 17:57:00+00 │ 1.5382691050147506 200 │ 2020-08-01 17:56:00+00 │ 1.6427718293547886 404 │ 2020-08-01 17:56:00+00 │ -0.41260101365496504 400 │ 2020-08-01 17:56:00+00 │ 2.75460015502278 500 │ 2020-08-01 17:56:00+00 │ -0.41260101365496504
WITH calculations_over_window AS ( SELECT status_code, period, entries, AVG(entries) OVER status_window as mean_entries, STDDEV(entries) OVER status_window as stddev_entries FROM server_log_summary WINDOW status_window AS ( PARTITION BY status_code ORDER BY period ROWS BETWEEN 60 PRECEDING AND CURRENT ROW ) ),with_zscore AS ( SELECT *, (entries - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore FROM calculations_over_window ),
with_alert AS (
SELECT *, zscore > 3 AS alert FROM with_zscore )
SELECT status_code, period, entries, zscore, alert FROM with_alert WHERE alert ORDER BY period DESC LIMIT 20;
status_code │ period │ entries │ zscore │ alert ────────────┼────────────────────────┼─────────┼────────────────────┼─────── 400 │ 2020-08-01 18:00:00+00 │ 24 │ 6.823777205473068 │ t 400 │ 2020-08-01 17:59:00+00 │ 12 │ 7.445849602151508 │ t 400 │ 2020-08-01 17:58:00+00 │ 2 │ 4.838594613958412 │ t 500 │ 2020-08-01 17:29:00+00 │ 1 │ 3.0027309973793774 │ t 500 │ 2020-08-01 17:20:00+00 │ 1 │ 3.3190952747131184 │ t 500 │ 2020-08-01 17:18:00+00 │ 1 │ 3.7438474117708043 │ t 500 │ 2020-08-01 17:13:00+00 │ 1 │ 3.7438474117708043 │ t 500 │ 2020-08-01 17:09:00+00 │ 1 │ 4.360778994930029 │ t 500 │ 2020-08-01 16:59:00+00 │ 1 │ 3.7438474117708043 │ t 400 │ 2020-08-01 16:29:00+00 │ 1 │ 3.0027309973793774 │ t 404 │ 2020-08-01 16:13:00+00 │ 1 │ 3.0027309973793774 │ t 500 │ 2020-08-01 15:13:00+00 │ 1 │ 3.0027309973793774 │ t 500 │ 2020-08-01 15:11:00+00 │ 1 │ 3.0027309973793774 │ t 500 │ 2020-08-01 14:58:00+00 │ 1 │ 3.0027309973793774 │ t 400 │ 2020-08-01 14:56:00+00 │ 1 │ 3.0027309973793774 │ t 400 │ 2020-08-01 14:55:00+00 │ 1 │ 3.3190952747131184 │ t 400 │ 2020-08-01 14:50:00+00 │ 1 │ 3.3190952747131184 │ t 500 │ 2020-08-01 14:37:00+00 │ 1 │ 3.0027309973793774 │ t 400 │ 2020-08-01 14:35:00+00 │ 1 │ 3.3190952747131184 │ t 400 │ 2020-08-01 14:32:00+00 │ 1 │ 3.3190952747131184 │ t
WITH calculations_over_window AS ( SELECT status_code, period, entries, AVG(entries) OVER status_window as mean_entries, STDDEV(entries) OVER status_window as stddev_entries FROM server_log_summary WINDOW status_window AS ( PARTITION BY status_code ORDER BY period ROWS BETWEEN 60 PRECEDING AND CURRENT ROW ) ),with_zscore AS ( SELECT *, (entries - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore FROM calculations_over_window ),
with_alert AS (
SELECT *, entries > 10 AND zscore > 3 AS alert FROM with_zscore )
SELECT status_code, period, entries, zscore, alert FROM with_alert WHERE alert ORDER BY period DESC;
status_code │ period │ entries │ zscore │ alert ────────────┼────────────────────────┼─────────┼────────────────────┼─────── 400 │ 2020-08-01 18:00:00+00 │ 24 │ 6.823777205473068 │ t 400 │ 2020-08-01 17:59:00+00 │ 12 │ 7.445849602151508 │ t 500 │ 2020-08-01 11:29:00+00 │ 5001 │ 3.172198441961645 │ t 500 │ 2020-08-01 11:28:00+00 │ 4812 │ 3.3971646910263917 │ t 500 │ 2020-08-01 11:27:00+00 │ 4443 │ 3.5349400089601586 │ t 500 │ 2020-08-01 11:26:00+00 │ 4522 │ 4.1264785335553595 │ t 500 │ 2020-08-01 11:25:00+00 │ 5567 │ 6.17629336121081 │ t 500 │ 2020-08-01 11:24:00+00 │ 3657 │ 6.8689992361141154 │ t 500 │ 2020-08-01 11:23:00+00 │ 1512 │ 6.342260662589681 │ t 500 │ 2020-08-01 11:22:00+00 │ 1022 │ 7.682189672504754 │ t 404 │ 2020-08-01 07:20:00+00 │ 23 │ 5.142126410098476 │ t 404 │ 2020-08-01 07:19:00+00 │ 20 │ 6.091200697920824 │ t 404 │ 2020-08-01 07:18:00+00 │ 15 │ 7.57547172423804 │ t
status_code │ period │ entries │ zscore │ alert ────────────┼────────────────────────┼─────────┼────────────────────┼─────── 400 │ 2020-08-01 18:00:00+00 │ 24 │ 6.823777205473068 │ t 400 │ 2020-08-01 17:59:00+00 │ 12 │ 7.445849602151508 │ t
WITH calculations_over_window AS ( SELECT status_code, period, entries, AVG(entries) OVER status_window as mean_entries, STDDEV(entries) OVER status_window as stddev_entries FROM server_log_summary WINDOW status_window AS ( PARTITION BY status_code ORDER BY period ROWS BETWEEN 60 PRECEDING AND CURRENT ROW ) ),with_zscore AS ( SELECT *, (entries - mean_entries) / NULLIF(stddev_entries::float, 0) as zscore FROM calculations_over_window ),
with_alert AS (
SELECT *, entries > 10 AND zscore > 3 AS alert FROM with_zscore ),
with_previous_alert AS ( SELECT *, LAG(alert) OVER (PARTITION BY status_code ORDER BY period) AS previous_alert FROM with_alert )
SELECT status_code, period, entries, zscore, alert FROM with_previous_alert WHERE alert AND NOT previous_alert ORDER BY period DESC;
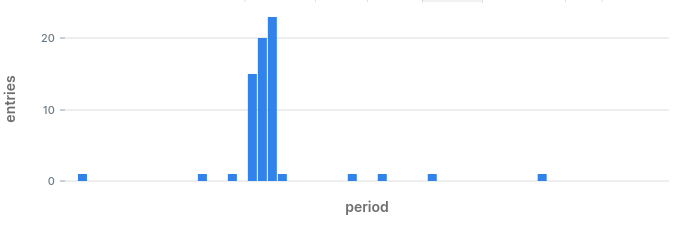
status_code │ period │ entries │ zscore │ alert ────────────┼────────────────────────┼─────────┼───────────────────┼─────── 400 │ 2020-08-01 17:59:00+00 │ 12 │ 7.445849602151508 │ t 500 │ 2020-08-01 11:22:00+00 │ 1022 │ 7.682189672504754 │ t 404 │ 2020-08-01 07:18:00+00 │ 15 │ 7.57547172423804 │ t
- Anomaly in status code 400 at 17:59: we also found that one earlier.
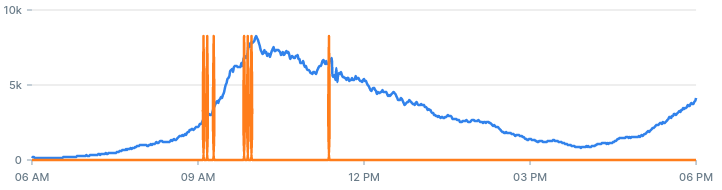
- Anomaly in status code 500: we spotted this one on the chart when we started.
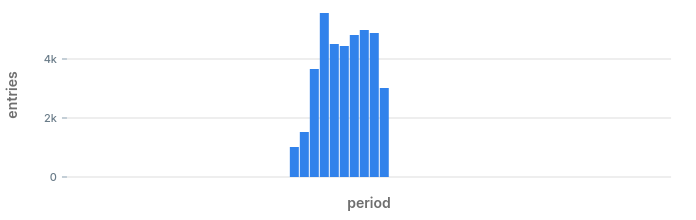
- Anomaly in status code 404: this is a hidden hidden anomaly which we did not know about until now.
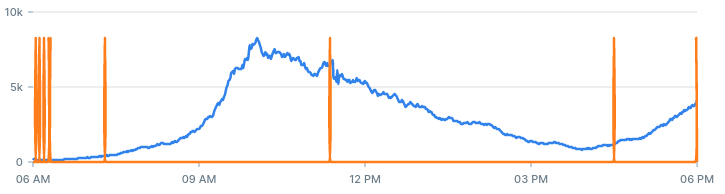
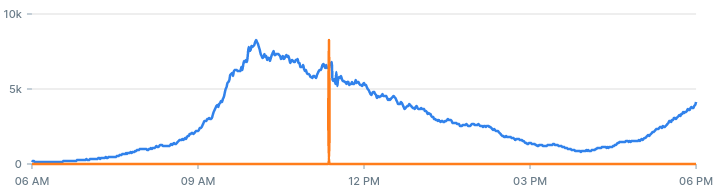
- Lookback period: How far back we calculate the mean and standard deviation for each status code. The value we used is 60 minutes.
- Entries Threshold: The least amount of entries we want to get an alert for. The value we used is 10.
- Z-Score Threshold: The z-score after which we classify the value as an anomaly. The value we used is 6.

{kind=link}
SELECT status_code, avg(entries) as mean, sum( entries * (60 - extract(‘seconds’ from ‘2020-08-01 17:00 UTC’::timestamptz - period)) ) / (60 * 61 / 2) as weighted_mean FROM server_log_summary WHERE – Last 60 periods period > ‘2020-08-01 17:00 UTC’::timestamptz GROUP BY status_code;status_code │ mean │ weighted_mean ─────────────┼────────────────────────┼───────────────────── 404 │ 0.13333333333333333333 │ 0.26229508196721313 500 │ 0.15000000000000000000 │ 0.29508196721311475 200 │ 2779.1000000000000000 │ 5467.081967213115 400 │ 0.73333333333333333333 │ 1.4426229508196722
2, 3, 5, 2, 3, 12, 5, 3, 4
SELECT percentile_disc(0.5) within group(order by n) FROM unnest(ARRAY[2, 3, 5, 2, 3, 120, 5, 3, 4]) as n;median ──────── 3
2, 2, 3, 3, 3 4, 5, 5, 12
2, 2, 3, 3, 3 4, 5, 5, 120
- To try and identify DOS attacks you can monitor the ratio between unique IP addresses to HTTP requests.
- To reduce the amount of false positives, you can normalize the number of responses to the proportion of the total responses. This way, for example, if you’re using a flaky remote service that fails once after every certain amount of requests, using the proportion may not trigger an alert when the increase in errors correlates with an increase in overall traffic.